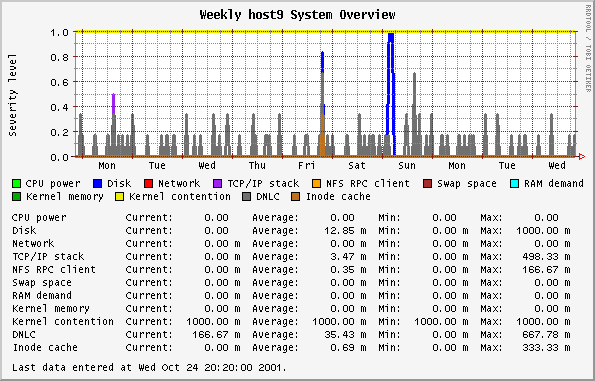
This graph is based on the SE classes that examine 11 different components of a system, such as disks, net, RAM, etc. The SE classes use rules determined from experience to represent the health of that component. This is all described very nicely in an article by Adrian Cockcroft. The rules in this 1995 article do not necessarily reflect the rules in any other SE releases.
The orcallator.se script goes beyond the determination of a state and assigns a numerical value to the state, which is then plotted. The numerical values grow exponentially to represent that as the state get worse, the represented component is in a much worse state than would be represented by a linear progression. The states and their values are:
-
0 - White state - completely idle, untouched
-
1 - Blue state - imbalance, idle while other instances of the resource are overloaded
-
2 - Green state - no problem, normal operating state
-
4 - Amber state - warning condition
-
8 - Red state - overloaded or problem detected
-
16 - Black state - critical problem that may cause processes or the whole system to fail
Any values over 1 warrant a look at.
Note: The colors in the plot have nothing to do with the colors representing state.
The values recorded by orcallator.se are twice the values plotted here. After I released orcallator.se I decided that having a component operating in an acceptable state (white, blue or green) resulting in values ranging from 0 to 2 is not natural to system administrators, where system loads above 1 mean the system is busy. The division by two makes this more intuitive.














































